So the post before last I wrote a summary of my summer RMMC trip to Wyoming. As readers of that post will know, the summer topic selected for that annual conference was algebraic graph theory. Many, many, MANY things were discussed there, so many that to write about all of them would be an unrealistic endeavor. It would be a shame not to mention at least one topic from the conference though, so today I will be discussing a particular class of graphs that turned up in several of the contributed RMMC talks: strongly regular graphs.
Those with some acquaintance with graph theory have most likely heard of regular graphs at the least. Those are the simple graphs (no loops nor multiple edges) where all of the vertices have the same nonnegative degree k. Examples of this include the empty graph (just includes a bunch of isolated points) of regular degree 0, the complete graph of regular degree n-1 (assuming n is the number of vertices in said graph), the Petersen graph (imagine what the drawing of the cocky looking guy above would look like if we only included the black dots and lines between dots) of regular degree 3, simple cycles which are regular of degree 2, and so on.
The focus of this posting is on undirected graphs, but for the sake of completeness it should also be noted that the notion of regularity can also be extended to directed graphs or digraphs. In this case saying that a digraph is regular means that the indegree of each vertex in the graph equals its outdegree. A very simple example of a regular directed graph is a cycle that has had its edges oriented clockwise or counterclockwise.
So the post before last I wrote a summary of my summer RMMC trip to Wyoming. As readers of that post will know, the summer topic selected for that annual conference was algebraic graph theory. Many, many, MANY things were discussed there, so many that to write about all of them would be an unrealistic endeavor. It would be a shame not to mention at least one topic from the conference though, so today I will be discussing a particular class of graphs that turned up in several of the contributed RMMC talks: strongly regular graphs.
Those with some acquaintance with graph theory have most likely heard of regular graphs at the least. Those are the simple graphs (no loops nor multiple edges) where all of the vertices have the same nonnegative degree k. Examples of this include the empty graph (just includes a bunch of isolated points) of regular degree 0, the complete graph of regular degree n-1 (assuming n is the number of vertices in said graph), the Petersen graph (imagine what the drawing of the cocky looking guy above would look like if we only included the black dots and lines between dots) of regular degree 3, simple cycles which are regular of degree 2, and so on.
The focus of this posting is on undirected graphs, but for the sake of completeness it should also be noted that the notion of regularity can also be extended to directed graphs or digraphs. In this case saying that a digraph is regular means that the indegree of each vertex in the graph equals its outdegree. A very simple example of a regular directed graph is a cycle that has had its edges oriented clockwise or counterclockwise.
With some basic notion of graph regularity we can know move on to the main post topic: strong graph regularity. When I hear strong regularity, I immediately think the implication is that a graph with such a property is regular in many ways, and this turns out to be true. In order to define a strongly regular graph a total of four parameters must be specified: n, k, lambda, and u. n is the number of vertices in the graph, k the degree of all vertices (i.e. strongly regular graphs are regular as defined previously), lambda is the number of common neighbors that every pair of adjacent vertices in the graph share, and u is the number of common neighbors that any two non-adjacent vertices of the graph share. Like many things in graph theory, the way to understand this is through visual example, so consider the Petersen graph. It has a total of n = 10 vertices and is regular of degree 3. A quick inspection of the graph should reveal that any two adjacent vertices share no common neighbors (implying that the graph is triangle free) and any two nonadjacent vertices have exactly one neighbor in common. By the above definition then we can classify the Petersen graph as a strongly regular ones with parameters 10, 3, 0 and 1 respectively. This is often expressed more compactly by saying that the Petersen graph is srg(10, 3, 0, 1).
So what makes strongly regular graphs so special besides their satisfaction of numerous regularity conditions? Well for one they have some interesting algebraic properties. If one was to calculate the eigenvalues of a strongly regular graph, it would be found to have exactly three distinct ones. Even more so, these eigenvalues can be expressed in terms of the parameters n, k, lambda and u. The complete derivation involves a few clever observations and careful tinkering with some equations.
The first eigenvalue is not hard to figure out. Because a strongly regular graph is regular of degree k, it must have k as an eigenvalue. The way to see this is by looking at the multiplication of the graph's adjacency matrix A with the all one's eigenvector. Since each row of A has k ones, multiplying the two will result in entries of k in the resulting vector (i.e. k times the original all one's vector).
Now, how about the remaining eigenvalues? To find them we have to make a few key observations. For one, remember that the (i,j)th entry of the adjacency matrix A to some positive power k is equal to the number of walks of length k from vertex i to vertex j. Knowing this we can deduce that the entries along the diagonal of A^2 are equal to the number of walks of length two from each vertex to itself. This is simply equal to the degree of each of the vertices. Similarly one can deduce that for all other entries A^2 gives us the number of paths of length 2 between the corresponding vertices, and this will in turn equal the number of common neighbors that the vertices share. The other observation to make concerns the expression of the adjacency matrix of the graph's compliment. If you let J denote the all one's matrix and I the identity matrix, then a little looking over should convince you that the compliment's adjacency matrix is J-I-A.
With these two observations and the definition of a strongly regular graph, the following equality holds:
A^2 = lambda*A + u(J-I-A) + kI
If this is not clear then remember that the number of two-walks from a vertex to itself is k in this case (so the k's along the main diagonal contributed by kI), the number of common neighbors of two adjacent vertices i and j will be lambda (hence the lambda*A contribution to A^2), and any two nonadjacent vertices in the graph will be adjacent in the complement and will have u neighbors in common (explaining the u(J-I-A) term which also contributes to A^2).
Through a little bit of distribution and simplification this equation becomes:
A^2 = (lambda-u)A + uJ + (k-u)I
Now remember that we are dealing with graphs here, and graphs have symmetric matrices. There is a result usually taught in matrix theory courses which says that the eigenvectors corresponding to the different eigenvalues of a symmetric matrix are orthogonal to each other. We already know one eigenvector, the vector of all one's. Any other eigenvector we find will be orthogonal to this. Suppose that for another eigenvalue then we have its corresponding eigenvector v and multiply both sides of the latest equation with that. It will then reduce to the following:
(A^2)v = (lambda-u)Av + (k-u)v
Notice that the uJ term cancelled out. This is because when multiplying J and v you are essentially taking the dot product of the rows of J with v. The rows of J consist of all one's and v is orthogonal to the one's vector,so the dot products will result in just a bunch of zeros.
We're almost there now!
Suppose that y is another eigenvalue of our strongly regular graph. Our third equation will then become
(y^2)v = (lambda-u)yv + (k-u)v
which implies that:
(y^2) = (lambda-u)y + (k-u)
This is a quadratic equation in y which can be solved to give us the remaining two eigenvalues for the original strongly regular graph! Cool! :-D
So that this post will not get too long I think that I will stop here and let the three distinct eigenvalues property suffice for strongly regular graphs (for the time being at least). Hope you all liked the post and the cartoon (like all others made in Paint by yours truly). As always, keep on graphing! :-)
 Hello dear readers and a Happy Pi Approximation Day (or as some also call it, Casual Pi Day) to all! :-D Now just like Yellow Pig Day I had no prior knowledge of this math holiday. Before Yellow Pig Day the only math holiday that I knew about was Pi Day. Imagine my surprise then upon finding out about another holiday related to Pi Day while perusing the internet for special events in July.
Excitement and wonder aside there is some explaining to do regarding Pi Approximation Day. First of all, why is it held July 22nd of all days? The answer is clear if you look at its date number 7/22 and take the inverse of that (or just look at it European style). That will give you 22/7 which is a pretty good approximation to pi (better actually than the 3.14 provided by the digits of the well established Pi Day. If you do the division you will see that 22/7 comes out to about 3.142857142857143. Besides this slightly closer approximation to pi I also find the notion of a pi approximation day more appealing than just a pi day since the best we can do with a finite number of digits is approximate the constant. Besides that, I also find the holiday appealing from a computer science perspective. It's natural to wonder how people have tried to approximate pi over the years and how people have been able to generate all of the immense digits of pi that are known today.
The literature on numerical methods for approximating pi is immense. A quick browse through left me getting excited over topic after topic after topic, and unsure what would be appropriate for this post. After discarding the notion of trying to write a comprehensive post on such methods, I decided to expand on a historical note on the topic (people have been trying to approximate pi since antiquity), which brings me to a name I'm sure many of you have heard: Archimedes. In relation to pi, he managed to produce surprisingly accurate bounds on the constant, approximating it to be greater than 223/71 and less than 22/7. His methods of proof involved a bit of geometry, specifically regular polygons with many sides inscribed within and around circles.
In much more recent years (relative to Archimedes' time) a very elegant mathematical proof surfaced of the upper bound: pi < 22/7. As Lucas notes, (see reference below), the integral that implies the result was first officially published by Dalzell in 1971, and may have been known a little earlier in the mid 60s by Kurt Mahler. This very special integral is shown below in my paint drawing (sorry for the rather unelegant drawing of the otherwise elegant integral; I don't believe that blogger has special symbols for mathematical formulae and I don't have any special math writing software).
Hello dear readers and a Happy Pi Approximation Day (or as some also call it, Casual Pi Day) to all! :-D Now just like Yellow Pig Day I had no prior knowledge of this math holiday. Before Yellow Pig Day the only math holiday that I knew about was Pi Day. Imagine my surprise then upon finding out about another holiday related to Pi Day while perusing the internet for special events in July.
Excitement and wonder aside there is some explaining to do regarding Pi Approximation Day. First of all, why is it held July 22nd of all days? The answer is clear if you look at its date number 7/22 and take the inverse of that (or just look at it European style). That will give you 22/7 which is a pretty good approximation to pi (better actually than the 3.14 provided by the digits of the well established Pi Day. If you do the division you will see that 22/7 comes out to about 3.142857142857143. Besides this slightly closer approximation to pi I also find the notion of a pi approximation day more appealing than just a pi day since the best we can do with a finite number of digits is approximate the constant. Besides that, I also find the holiday appealing from a computer science perspective. It's natural to wonder how people have tried to approximate pi over the years and how people have been able to generate all of the immense digits of pi that are known today.
The literature on numerical methods for approximating pi is immense. A quick browse through left me getting excited over topic after topic after topic, and unsure what would be appropriate for this post. After discarding the notion of trying to write a comprehensive post on such methods, I decided to expand on a historical note on the topic (people have been trying to approximate pi since antiquity), which brings me to a name I'm sure many of you have heard: Archimedes. In relation to pi, he managed to produce surprisingly accurate bounds on the constant, approximating it to be greater than 223/71 and less than 22/7. His methods of proof involved a bit of geometry, specifically regular polygons with many sides inscribed within and around circles.
In much more recent years (relative to Archimedes' time) a very elegant mathematical proof surfaced of the upper bound: pi < 22/7. As Lucas notes, (see reference below), the integral that implies the result was first officially published by Dalzell in 1971, and may have been known a little earlier in the mid 60s by Kurt Mahler. This very special integral is shown below in my paint drawing (sorry for the rather unelegant drawing of the otherwise elegant integral; I don't believe that blogger has special symbols for mathematical formulae and I don't have any special math writing software).

With a little bit of Calculus 2 knowledge the integral will not be hard to evaluate (though maybe a little time consuming to expand in the numerator). To evaluate you expand the numerator and divide by the denominator. After long division there will be one term at the end that has a (1 + x^2) in the denominator. The thing to remember with that is the antiderivative which is the arctangent function. Evaluating the expression at the upper and lower bounds and taking limits as necessary will give the answer of 22/7 - pi. The answer will be positive because the integrand is positive and the upper integration limit of 1 is greater than the lower limit of 0. Together you get the awesome magical inequality of 0 < 22/7 - pi which implies that pi is less than 22/7. Pretty cool.
Some readers may wonder where such a magical integral could have come from. Did it just pop out of the sky or is there some deeper mathematical pattern underlying all of this? It turns out to be the latter. The above integral can be generalized to arbitrary powers m and n for x and (1-x). This generalization was recently introduced by Backhouse and can provide many more approximations of the constant pi. The reason this is so is because it will evaluate to ax + b*pi + clog2. The coefficients a, b and c are all rational, a and b have opposite sign, and if it is the case that 2m is congruent to n modulo 4, then c will equal zero (Backhouse proved this) and we once again have a result like ax + b*pi > 0. As m and n increase the results to pi will become finer and finer. Even more so, it turns out that this is not the only such integral that provides approximations of pi. A skimming over the Lucas reference provided below will show another similar integral as well as a table comparing the approximations provided by the two integrals with increasing values of m and n combined.
And that's that my dear readers. It would be great to continue exploring approximation methods to pi, but if you are in more of a casual pi day kind of mood then I recommend snacking on some tasty tarts (especially pecan: my favorite!, they kind of look like/approximate pies too) lay back, listen to some Herb Alpert, and take it easy. :-)
References:
1. N. Backhouse, Note 79.36, Pancake functions and approximations to , Math. Gazette 79 (1995),
371–374.
2. S.K. Lucas, Integral proofs that 355/113 > pi, Gazzette Aust. Math. Soc.
32 (2005), 263–266.
It was for the latter half of June that I had the privilege of attending the University of Wyoming's annual Rocky Mountain Mathematics Consortium (RMMC) summer program. It lasted for about a week and a half, and everyday (except for the weekends) was filled with three main lectures by notable researchers in the selected RMMC topic. Graduate students and a few professors took the time in between lectures to present contributed talks. What attracted me to the program was the topic: algebraic graph theory. On my own independent readings I had come across material discussing the relations between a graph's spectra and the properties of said graphs (e.g. graph connectivity, bipartiteness, vertex valencies...). It amazed me at those times how much you could say about a graph by looking at the eigenvalues of its adjacency matrix (it still does now!). Given this short enthusiastic blurb on graph spectra along with all of my previous graph theory posts, I'm sure my readers can imagine how incredibly stoked I was when I received word of acceptance to the conference/program.
The three lecturers for RMMC were Chris Godsil of the University of Waterloo, William Martin of Worcester Polytechnic University, and Joanna Ellis-Monaghan of Saint Michael's College. Their lectures covered material on quantum graph walks, coding theory, and graph polynomials respectively. I purchased a notebook before my trip to Wyoming expecting that I had more than enough paper for RMMC, but at the end of it all I had a notebook completely stuffed with graph theory ideas; not an inch of white space to spare! Among the topics discussed (both from lectures and from contributed talks) were the following (and do note that this is only a small sample listing; the list goes on and on and on!): edge deletions and contractions, the Tutte polynomial, strongly regular graphs, Hamiltonian cycle detection, graph energy, the spectral decomposition of graphs, Hadamard matrices, n-cube graphs, graph toughness (this was actually discussed the Sunday before the program actually started), linear programming methods for the social networking influence maximization problem, eigenvalues of directed graphs, and some knot theory basics. Phew! :-0 To review the daily material presented in main lectures, we also had a problem solving session at the end of every other day. During these problem solving sessions we could ask the lecturers questions about the problems they made up and collaborate with other students on them.
Among the many graduate students I met at the conference, there were two I spent many of my problem solving sessions with and got to be great friends with. Pictured below are the three of us. That is of course me in the middle, and to my left and right are Saba and Danielle.
The picture setting was a banquet that RMMC held for all of us during the last week we were there (hence the fancy glasses and table cloths). It was a great dinner and a time to take lots of pictures and relax after all of the hard studying and work. RMMC was a great experience and it is very possible that I will discuss it or at least some of the topics presented there more in future posts. :-)
So far all of the posts on this blog have been about graphs, be
they directed, undirected, simple, non-simple,..etc. That's great and graphs are my favorite, but for this post I thought that I'd shake things up a bit...talk about something similar but wacky at the same time ya know? Any guesses? ;-D Well if you read the title of this post it probably won't take you that long to figure it out. This post will be about the less studied but more generalized graph theoretic concept of hypergraphs.
Now I had heard of hypergraphs before, but until now I hadn't set aside enough time to really study them. What I picked up from my brief skimmings of the hypergraph literature was that the edges in hypergraphs could connect more than 3 vertices (in contrast to the graphs that we know where edges are associated with just two vertices). The idea sounded pretty abstract and different to me. No inkling of an idea as to their applications in pure or applied mathematics. To my surprise then when I found out very recently that hypergraphs are being used to store database information.
WHAAAAAAAAAAAAAAAAAAAAAAAAAAATTTTTT???!!!! :-O
I know I know. You're probably all about as surprised as I was and no doubt itching to read on about the database business. To be as thorough as possible though and to really appreciate the ideas behind the application, let us first look at a more formal definition of hypergraphs and extend that notion to directed hypergraphs. My previous blurb about a hypergraph having "longer" edges will simply not do.
A graph as I'm sure most of you know, is often defined in more formal terms as a pair of sets V (for the vertices) and E (for the edges). Hypergraphs are also defined in terms of two sets. These can also be denoted as V and E for the vertices and edges respectively. The vertices of a hypergraph are like the vertices of regular graphs; nothing unusual there. The edges though are defined to be non-empty subsets of the vertex sets. If all of the edges in the hypergraph are sets of cardinality two, then we have the regular graphs that we are used to dealing with. Note though that graphs are just special cases of hypergraphs. Following the above definition it is possible to have hypergraph edges that consist of 3 or more distinct elements of the vertex set.
A natural thought that may creep into your mind is, how are hypergraphs visualized? From what I have seen I don't think that that area of graph visualization has been studied very much (at least relative to the visualization of regular graphs). So far I have only seen two ways of visualizing hypergraphs. The first way simply draws a line or tree connecting the vertices of an edge and assigns an edge labeling to make it clear that the edge covers 3 or more vertices rather than two. The other way that I have seen hypergraphs drawn is by visualizing the vertices of an edge all within some colored blob (being real technical here). Seeing two edges intersect within such a drawing is similar to seeing two sets of a Venn Diagram intersect.
With the basic idea of a hypergraph in mind let us now see how things like paths and cycles can be generalized in the hypergraph sense. A walk of length k in a hypergraph is defined to be a sequence of k vertices v1 v2,...., vk where vi and vi+1 are contained in a common edge. A path in a hypergraph is then defined to be such a walk in which all of the vertices and edges are distinct. In a closed walk the beginning and ending vertices are the same, and likewise a closed path is a path where the starting and ending vertices match. If any of these definitions sound odd to you just remind yourself about the simplest case in which the hypergraph is a regular graph. Looking at things that way helps to give a more set theoretic view of the graphs that we are used to dealing with.
The last (or on second thought second to last) generalized graph concept that I thought I would touch up on before getting to the fun database application is the extended hypergraph notion of subgraphs. Remember that subgraphs are basically graphs contained within graphs. They consist of pairs of sets V' and E' where V' and E' are both subsets of the original graphs vertex and edge sets V and E. The definition of a sub-hypergraph is a little bit more involved. Let J = {1,2,...,k} be an indexing set for a subset of hypergraph edges E1, E2,...Ek. Also, let V' be a subset of the hypergraph's vertices. The sub hypergraph induced by V' and J is defined to be the set of intersections between each Ej and V' where the Ej's range from 1 to k and the intersections considered are the nonempty ones. Again it's good to step back from this more abstract notion of subgraphs and think about how this relates to the simpler graph case. In that scenario imagine that the indexing set J goes from 1 to m for all of the m edges in the graph. The above definition then boils down to finding the resulting graph in which the only edges considered are the ones that have endpoints in the vertex subset V'.
The final notes to make (before moving onto applications) which is really important for this post is the following. Just as hypergraphs generalize the idea of graphs, hypergraphs can also be generalized a bit. How? Well, rather than just pointing to nodes (and again it's assumed that hyperedges can correspond to 3 or more nodes) hyperedges in a more generalized view can "point" to other edges as well. This is the approach that is taken by the database application that we will now touch on.
This database application is called HyperGraphDB. What it is is an embedded database that uses a hypergraph as its underlying storage mechanism. The nodes and edges (or links as HyperGraphDB calls them) are all categorized as "atoms" of the database (atoms are basically just database entities/objects). The links can of course point to any number of atoms, consistent with the general definition of a hypergraph. The particular example that I have shown here (as bolded code line below) makes use of HyperGraphDB's HGValueLinkg class. There are several link classes defined within HyperGraphDB, HGValueLink being the one you use when you want to associate some sort of value (can be any kind of object) with your hyperedge. In this example I represent my name with a String and pass it as the first argument to the HGValueLink constructor. What comes after that is an array named nodes. Not surprisingly, this array holds information relating to the nodes (and/or links) that are to be contained within the link variable hyperedge.
HGValueLink hyperedge = new HGValueLink("Tanya", nodes);
Now some of you may be wondering, what exactly is the nodes array? What kind of information does it hold? It turns out that the array does not hold regular object references to the nodes being "connected", but rather to their associated "HGHandle"s. HGHandle is another class defined within the core api. They serve as identifiers for the objects added to the database. For the most part (there are exceptions to this) you will need to refer to an object's handle if you want to do something with it. This is definitely the case when your desire is to remove a node or link from the database. There are times when you can still refer to an atom through it's Java object reference, but from what I've seen so far HyperGraphDB is different in that it emphasizes the use of these handles rather than the traditional approach of using object references to get to things.
The list of HyperGraphDB's capabilities goes on and on, but I will stop here as the main point of this post was to name a hypergraph database application and show how it conforms to the hypergraph definitions explained earlier. One thing you may still be wondering is, why would someone ever want to use a hypergraph database? What are they good at modeling? The answer depends on what type of data you are looking at and the information that you aim to get out of your data. One of the simplest examples that I could think of is the following. Suppose that you wish to model some of your Google+ hangouts data as a graph. You and all of the people that you have hung out with are the nodes of a graph, and an edge exists between two nodes if the corresponding people hung out. Even if you and two of you hangout buddies all form a cycle, there is no way of telling from this very basic graph model if let's say 3 of you were in a hangout all at the same time. To do that you may have to add information to the nodes and/or edges, partition your vertices into two groups where one of the groups represents people and the other a hangout on a given day or time, or as this post would suggest, model your hangouts in hypergraph style. All of the people involved in the same hangout will be contained within the same hyperedge. This underscores the extreme flexibility of hypergraphs in one sense, but also shows how the best solution can really depend on the problem at hand and what you hope to accomplish.
If anyone has worked with HyperGraphDB or just hypergraphs as models in general please leave a comment. I am eager to learn more about hypergraphs! :-D
In case you didn't know, March 1st was Pig Day, one of the lesser known national holidays here in the U.S. of A. I like to quietly celebrate this day by sending out lots of pig pictures to friends via email. Oink! :=) Now even if pigs had absolutely nothing to do with math I would still be tempted to make a posting for them. Why? They are wonderful, intelligent and multitalented creatures. Just do a generic google search on pig intelligence or go looking for them on youtube. In the latter case you'll eventually (if not immediately) stumble upon videos of pigs shaking hands, playing soccer, bowing,singing,..etc. In fact, I've often heard that those who keep pigs as pets have to make sure to keep them mentally occupied. They're smart creatures and are always looking for new things to discover and challenge their minds with.
As it so happens though, pigs do have something to do with math apart from performing calculations for audiences. The link comes through another holiday, Yellow Pigs Day! (celebrated July 17th. What do people do on this day? They eat yellow cake, exchange yellow pig gifts, sing songs and carols about yellow pigs, and think of properties of the number 17. That's an odd sounding festivities list, but with a little background information it will make a bit more sense. I am not sure when Yellow Pig Day was added to the holidays list, but its yellow pig origins can be traced back to the 1960's. Whichever year it actually was, two math students, Mike Spivak and David C. Kelly, were given the assignment of analyzing properties of the number 17. After spending some time mulling over the problem (mind you that 17 has many interesting properties), the two began to joke about a mythical yellow pig with 17 legs, 17 eyelashes (can't remember if it was on each eye or combined...), etc. From that period of hard work and yellow pig musings eventually evolved what we now celebrate as Yellow Pigs Day.
So that explains where the yellow pigs and 17's come from! Interesting huh? :-) This post would not be complete though without mentioning at least one property of 17. I have seen many long extensive lists of the properties of 17 (e.g. its arithmetic properties, its occurrence in architecture, its appearance in important dates and events,..etc.), but what I have not seen much of are the properties of 17 that relate to graph theory. In fact, I have only come across a few. The one that I will discuss here has to do with what are called Ramsey numbers.
It turns out that there is a whole area of combinatorics research referred to as Ramsey theory. One subcategory of Ramsey theory involves the aforementioned Ramsey numbers which in turn relate to colorings and cliques of complete graphs. At the most basic level this kind of problem can be stated in the following way:
What is the minimum number R(r,b) such that all complete graphs on R(r,b) vertices with edges colored red or blue contain a complete subgraph of r vertices with all red edges, or a complete subgraph of b vertices with all blue edges. The number R(r,b) is a Ramsey number.It has been proven that such a number exists.
The definition may at first be a little confusing, so the best way to understand it is by considering the following classic problem: show that at a party of 6 people there are 3 who all know each other or three who all don't know each other. Rephrased in graph theory terms the problem boils down to showing that any blue-red edge coloring of the complete graph K6 contains either a 3 cycle of blue edges (Remember that a 3-cycle is K3) or a 3 cycle of all red edges. This interesting factoid can be verified pretty quickly by experimenting a little with edge colorings on K6. As it also turns out, K6 is the minimum complete graph that satisfies this. Trying the same thing out on K5, K4, K3, K2 and K1 will yield nada. To again state things in graph theory lingo, this means that 6 is equal to the Ramsey number R(3, 3).
This idea of having a minimum number associated with 2 colorings and monochromatic subgraphs can be extended to three or more finite colors. In particular suppose that you have c colors and c integers n1, n2,...nc. The extended result says that there is a complete graph on R(n1,..,nc) vertices and c colors such that for some i between 1 and c there is a complete monochromatic subgraph of color i. The smallest number R(n1,...,nc) that satisfies this property for integers n1,..,nc and c colors is the associated multicolor Ramsey number.
And that my graphsters and graphistas is all of the background that you will need to understand this post. Phew! Let me now state a very special graph property involving the number 17. Ready.....(drum roll). Wait for it....and...Now!
R(3, 3, 3) = 17.
Virtual applause. :-D
As with all of the things that I write about I like to find out whenever I can when something was proven and by whom. I did a little bit of searching for the information behind R(3,3,3), and after some snooping through the internet found that the multicolor Ramsey number R(3,3,3) was originally found by Greenwood and Gleason in 1955. In addition to the result, what really strikes me as amazing is the way in which it was proven. Evidently Greenwood and Gleason used finite fields to prove their result. Finite fields and graph theory are not two subjects that I would immediately associate with each other. An unexpected surprise. Awesome!!!! :-D
P.S. Oink!
It's another day in my graph visualization journey and I am about half way up my climb of "Mount Sugiyama". I've passed the first sign on the trail of no cycles, and after a little bit of huffing and puffing I have finally cleared my way through the layers of boulders and rocks scattered across what is claimed to be the longest path in the hike. Phew! With some minutes now to contemplate my journey thus far I thought that I would describe some of the things encountered during my most recent excursion through Mount Sugiyama.
Now I honestly don't know if there really is a Mount Sugiyama out there. I've gone hiking many times, but have never had the opportunity or gumption to go scaling up one of 'em big ole mountains. Intellectually though I consider myself to be going on a hike of sorts, this hike being through the Sugiyama drawing framework mentioned in an earlier post. In that post I listed the four general steps of that framework which I will repeat now:
1. remove all directed cycles in your input digraph
2. partition the vertices into groups/layers. The edges of the graph will run between these layers.
3. reorder vertices within layers so as to reduce edge crossings
4. reassign vertex x-coordinates
I have already discussed the first step in a previous post so now on to the second step: layering (i.e. the treacherous path of Mount Sugiyama!!!!)
Before going into algorithm details we should first remember the main purpose of the Sugiyama method: to visualize a directed graph in hierarchical fashion. After giving your digraph the layering treatment it should look something like the following illustration, with vertices bunched into groups/layers and the majority of edges pointing in one direction (up, down, left, right,...etc.). It is the layering step that is responsible for the nice partitioned vertex sets and the uniform edge flows.

Now, how exactly is layering accomplished? As with the first task of removing directed cycles, many different algorithms have been proposed for this problem, each with its own set of advantages and disadvantages. Of all of the layering algorithms in existence the simplest is what is often referred to as the longest path algorithm. It basically works by building up the digraph's layers in a bottom up fashion so that the majority of edges are pointing down. Here is a summary of the algorithm's pseudocode:
Input: directed acyclic graph G = (V, E)
Output: layering
Initialization:
create two empty sets V1 and V2
create an integer variable currentLayer = 1
while |V1| < |V| (Here |V| means the cardinality of V and ditto for V1)
Select a vertex v in V\V1 s.t. all of its outgoing neighbors form a subset of V2. If such an element exists then assign it to the current layer and append it to U.
Else increase currentLayer by one and let Z be the union of Z and U.
The algorithm is simple enough to explain, but it's extremely important to understand exactly what is going on. Let's look at the first selection statement. At the very beginning of each while loop iteration we are trying to find a vertex such that all of its outgoing neighbors form a subset of V2. V2 is initially empty so the step starts by looking for vertices that have no outgoing edges, namely the sinks. Every time that a sink s is found it is assigned to layer 1 and appended to vertex set V1. Following the algorithm you will continue to do this until no more sinks are left. Note that there will be at least one vertex in layer 1 since every digraph has at least one sink (See if you can prove this! Proofs are fun :-D ).
After handling all of the sinks we now reach the point where there is a vertex with positive outgoing degree. Its set of outgoing neighbors clearly can not be a subset of the empty set V2. So we increment currentLayer to 2, take the union of V2 with V1 so that it now has all of the graph's sinks, and troop on.
Again, we check to see if there is a vertex not yet processed that has all of its outgoing neighbors contained in the previous layer(s). Assuming that we just finished handling all of the sinks the question is, is there a vertex that has nothing but sinks as its outgoing neighbors? The answer is yes (again try to prove it! Leave a comment if you would like to see a proof of this and the previous claim ;D ). So we assign that vertex to the currentLayer which is 2, and proceed. If an unprocessed vertex has at least one neighbor that isn't assigned to a layer, then we are forced to increment currentLayer and take the union of V2 and V1. The observant reader should note that the topmost layer will contain the source(s) of the digraph.
The very crucial part that I want to point out here is the condition that a vertex can not be assigned to a layer until all of its outgoing neighbors have been given layers. This is the condition that ultimately creates the uniform edge flows in our hierarchical drawings. The edge flow produced by this algorithm will be from top to bottom. If you assign a vertex to a layer before one of its outgoing neighbors, then you will get an edge pointing up (against the flow) once that particular neighbor is processed. That is not what we want in this kind of drawing, so when programming the longest path algorithm, be sure to check the status of all of the outgoing neighbors of a vertex before giving it the layering treatment. The only time in the Sugiyama method that you will tolerate having edges against the flow is after layering is complete. Once that part is done you can reinsert or reverse the direction of edges that were handled when removing directed cycles (Step 1).
So yeah...remember that!
A few last things I thought I would point out about longest path layering concern its computational and aesthetic pros and cons. Pros: the algorithm is simple, runs in linear time, and constructs a hierachical layout with minimum height.
Cons: Other aesthetic criteria such as edge densities and drawing width are not met so well by the algorithm. In particular, drawings produced by the longest path algorithm tend to be wider at the bottom.
Remember that too! :-D
As with all of my graph theory posts I really enjoyed researching the material for this one. It's fascinating that there are so many different ways of approaching graph drawing, a problem that initially sounds easy but becomes much more detailed and complex upon further inspection. I like to think of the algorithms and heuristics that I pick up on my graph visualization journey as pretty little gems nested inside the walls of a deep dark cavern. Because I enjoyed discussing layering so much, it is possible that I may revisit this topic in a future post. If so then I will most likely discuss another algorithm that is commonly used for layering, the so-called Coffman-Graham algorithm. Until then, keep on graphing and don't be afraid to go searching for some gems to add to your algorithms collection. :-)
At some point in our lives we're bound to encounter square roots; e.g. what's the square root of 4, or the square root of 9? I'm trying to remember the first time I came across those in school. Middle school? Fifth grade? Do you remember when you first saw square roots? Ahhhh....nostalgia. :-)
 (Snapping out of it) Okay, so uh.....advancing further along the algebra path, we then start to see square roots of not so "perfect" numbers (e.g. 8, 14, 39, 45). Unlike 4 or 9 we can't find whole numbers that when squared will match these exactly. It won't work! Never ones to admit defeat, we roll up our sleeves, manipulate 'em radicals, and figure out how to at least simplify said square roots (or use our calculators if all else fails! not recommended though :-P.....I MEAN IT). That's fine and most of us will then choose to stop our little "land of square roots" family vacation there. There are always a few brave souls though with a taste for danger who will decide to venture on (show-offs). First stop: the "imaginary sulfur pits" (ominous and foreboding music starting to play). Below is an account recorded by one of these adventurers. His name is not mentioned as he would like to protect his anonymity. :-)
(Snapping out of it) Okay, so uh.....advancing further along the algebra path, we then start to see square roots of not so "perfect" numbers (e.g. 8, 14, 39, 45). Unlike 4 or 9 we can't find whole numbers that when squared will match these exactly. It won't work! Never ones to admit defeat, we roll up our sleeves, manipulate 'em radicals, and figure out how to at least simplify said square roots (or use our calculators if all else fails! not recommended though :-P.....I MEAN IT). That's fine and most of us will then choose to stop our little "land of square roots" family vacation there. There are always a few brave souls though with a taste for danger who will decide to venture on (show-offs). First stop: the "imaginary sulfur pits" (ominous and foreboding music starting to play). Below is an account recorded by one of these adventurers. His name is not mentioned as he would like to protect his anonymity. :-)
Recording:
Well there's nothing even trying to be imaginary about the smell. I'm catching a strong whiff of something resembling eggs (makes me think of my Aunt Edna's egg salad...uggh). The smoke's starting to depart now. There appear to be several piles of rocks surrounding the yellowish pit, each inscribed with various symbols: a bunch of lower case i's and -1's, the latter all surrounded by square root symbols. The writing looks pretty old. Were these ruins created by a long lost civilization? If so what was with their fixation on the 9th letter of the alphabet? Even more disturbing though: did the ancients know how to do their math because they keep on trying to take the square root of a negative number: impossible! Hmmmmm....what to do? I think I'll pull out my trusty math guidebook from the glove department. It probably has something to say about this.
(flipping pages)
Ah! Here we are! Imaginary numbers (explains the "imaginary" sulfur pits at least). And look here! It says that you can define a whole new set of numbers as an extension to the real numbers, denoting them collectively as C. Within this numbering system it is possible to take the square roots of negative numbers, the very base case being the square root of -1. Rather than writing -1 with a square root symbol over and over again it recommends denoting the square root of -1 as i. Helps to make simplifying complex radicals easier I suppose. Oh and look hun! There's even a cute little example here where it shows you the square root of -4: 2i and -2i. I get there being two square roots but this still seems a little weird. Hughh.... there's even a coordinate system on the next page where the x and y axes are also complex. How odd! It says for further information either directly ask for a park ranger who knows complex analysis or go read a freakin' textbook! How rude!
This family vacation keeps on getting curiouser and curiouser (Alice in Wonderland moment). The sulfur pits were alright, a little different for me to get my mind around. Kind of cool though. What do you say kids? You ready to call it a day or did you still want to check out the museum of petrified matrix roots? (Loud protesting noises and shouts of excitement in the background). Ahhh very well. Onto the museum then.
(fast forwarding tape recorder)
And here we are! Final destination stop: the museum. It looks nice enough. There are display cases everywhere filled with samples of petrified matrix roots. In the center of each display case is a black and white picture of a diagonalizable matrix. Below said pictures are roots that have been supposedly extracted from the matrices.The museum lady says that they're all from the forest of Diag'ble matrices, donated by generous mathematician patrons from around the world. Let's see how many there are: 1, 2, 3, 4, oh my goodness! 5, 6, 7, and 8!!! I thought that matrices just had two roots, you know, like the stuff at the sulfur pits and the radicals shown on the signs leading up to there. How on earth could something have more than 2 roots? Hmmmnnnn.... the sign by this display case might give a hint; or rather a whole explanation. It reads as follows:
Square Roots of Matrices:
The square root of a square matrix A is a matrix B such that when you square B you get A. How does one find these square roots and how many of them are there? The first temptation that many might have is to simply take the square root of each of the entries within matrix A and call it a day. If you test out your answer though you will see that in general due to the way matrix multiplication is defined, this approach will not give you back your original matrix A. A way to get to the square root of the matrices shown here is a bit more involved than that.
The matrix shown in the above picture was taken from the forest of Diag'ble matrices in the year 1895. Although it is quite old, due to the preservation techniques of volunteering mathematicians it has maintained all of its properties since then, namely that it is still diagonalizable. This means that it can be written as the product of three matrices: (S^-1)*D*S (or equivalently as the product T*D*(T^-1)for some matrix T and diagonal matrix D). Here S is a matrix that has an inverse (denoted as S^-1) and D is a diagonal matrix that just has zero entries off of the main diagonal (diagonal entries may be zero as well).
It is keeping this form in mind that one can then extract roots like the petrified ones displayed below said picture. To find them you take the following steps:
1. Find the eigenvalues of matrix A.
2. Find eigenvectors that correspond to the eigenvalues of #1.
3. Form S from the eigenvectors of #2.These eignenvectos will be the columns of S.
4. Compute the inverse of S.
5. The diagonal entries of D will correspond to the eigenvalues of A. Their ordering on the main diagonal will in turn depend on the ordering of the eigenvectors in S. E.g. if eigenvector x1 is put into column 1 of S, then its associated eigenvalue will be the first main diagonal entry of D. If eigenvector x2 is designated as the second column of S, then its eigenvalue will be the second diagonal entry in D,.., and so on.
6. Find a square root of D and denote it as D*. Calculating a root is very simple in this case: because of the form of diagonal matrices you can simply take square roots of all of D's entries. Since each nonzero number within D can have two real square roots, this can potentially create up to n^2 different real D*'s.
7. SD*(S^-1) will all qualify as square roots of matrix A. Notice that there will be as many roots of this form as there are roots of D, explaining the case of having at least 8 square roots.
End of plaque explanation
Well that makes some more sense when explained like that. Pretty amazing that you can have more than 2 square roots for a matrix! And I thought that all of that facebook and twitter stuff was crazy! What do you think about all of this kids?.....Kids?
Ahhh...looks like they've gone straight to the gift shops. Better go chase 'em down before they try and destroy everything.
End of Recording
Well that was errghh..enlightening. I decided to leave the complex roots part to the park rangers and go on with providing a bit more explanation of the matrix roots discussion through example. Here is a 3 by 3 matrix that I grew for myself out of a Diag'ble tree seedling I found myself. :-) Following the steps outlined above let's see if we can spot some of its roots!
First of all here is the lovely 3 by 3 matrix:
A = [9 -5 3]
[0 4 3]
[0 0 1]
Since the matrix is triangular its eigenvalues are the numbers along its main diagonal: 9, 4, and 1.
With a little bit of calculation involving the equation (cI - A)x = 0 (c denotes one of the above 3 eigenvalues, x is an eigenvector), you will find that the following 3 eigenvectors work (I will denote them as x1, x2 and x3).
x1 = [1 0 0]
x2 = [1 1 0]
x3 = [-1 -1 1]
For the matrix S I'll let the columns from left to right be the eigenvectors x1, x2 and x3 correspondingly.
S = [1 1 -1]
[0 1 1]
[0 0 1]
I did enough paper and pencil matrix calculations this past week, so I'll just let you know (and trust me it's correct) that the inverse of this matrix S is the following (to find the inverse you can form the augmented matrix from S and the identity and successively do row operations on both sides until the left side is the identity matrix).
S^-1 = [1 -1 2]
[0 1 -1]
[0 0 1]
We're almost done now! The diagonal matrix D will have the eigenvalues 9, 4 and 1 placed in order according to the order of the eigenvectors within S. As mentioned earlier a square root of D can be obtained by taking the square roots of each of its diagonal entries.
D = [9 0 0]
[0 4 0]
[0 0 2]
Example of a square root of D:
D* = [3 0 0]
[0 2 0]
[0 0 1]
Notice that there is not one unique square root of our diagonal matrix D; each of the elements along the main diagonal of our sample square root can be positive or negative. When squared they will all yield the same result D. Thus there are at least 8 roots of matrix D which in turn implies that there are at least 8 roots for A (again this is because when you square S*(D*)*(S^-1) you get back S*D*(S^-1), A diagonalizing representation of A). Pretty cool! :-D Now is anyone up for checking out those imaginary sulfur pits? ;D
Captains Log: Stardate: uggh........ (Zap Brannigan voice)
It's another day into my graph visualization journey and I've had a lot to think about during my random walks in the graph theory world (joke...get it? ;D ). I've always had an interest in graph visualization, but the real kickstarter for my current journey was a project for visualizing user input graph data that I am currently working on. The first and most basic graph drawing methods I started looking into for the project were circle-based layouts (see previous post on circle-based graph drawings). Soon after that I heard about BioFabric and had my mind totally blown. As it turns out the timing of my BioFabric discovery coincided with the second type of drawing method on my visualization to do list: layered graph drawings!
I mark it as a special coincidence because of one similarity that the two methods have: layering. Now to be completely clear they ARE NOT the same thing! Layered graph drawing algorithms are meant to convey hierarchical information within a graph, whereas BioFabric is a tool for visualizing large and complex networks to make pinpointing things like clusters and graph structure more easy (i.e. its primary goal is not to clarify hierarchical dependencies). What I was just trying to point out was a parallel that I noticed between the two in that with layered graph drawings the vertices are aligned in layers with edges in between (the vertices in this case are still dots mind you), while in BioFabric the vertices are layered with edges in between layers as well but each vertex constitutes its own layer. (and most importantly, the vertices are no longer dots but LINES! REMEMBER THAT!!!). Perhaps as Adam Smith would say there is an invisible hand guiding me in my graph journey. That or maybe this kooky girl started getting some crazy ideas while out walking her dog!
Anywho, let's get on to the meat of the post: layered graph drawings! If you do a Google search of layered graph drawings, you're going to see the Japanese name Sugiyama pop up all over the place. That is because the framework associated with it describes the most common and popular method for creating layered/hierarchical graph drawings.It got its name from one of the men behind it, Kozo Sugiyama.
The goal of the Sugiyama approach is to draw a directed graph (or digraph for short) in a hierarchical fashion where you have vertices grouped with other vertices into layers, and most of the directed edges flow according to some direction (could be top to bottom, bottom to top, left to right,..etc.). Visualizing a directed graph in this fashion can give you a sense of hierarchy with the data and also convey dependency relationships more elegantly than if drawn otherwise. The simplest example that I can think of relating to this idea that also happens to show up all the time in computer science involves rooted trees. In many computer science applications you will have a tree with some designated vertex drawn at the top or bottom of the tree that is referred to as its root. From there you have leaves (the nodes at the very bottom of the tree/eh...or top) and internal nodes which are just the rest of the tree's vertices. It is almost always the case that your rooted tree's nodes are all drawn with a layering approach (the different "layers" being called the levels of the tree). The neighbors of the vertices in the graph are appropriately called its ascendants or descendants, implicitly giving the graph some sense of direction if directions are not already assigned to the edges. Here is a sample rooted tree produced by moi via Paint. :-)

Of course, the real utility of layered graph drawing methods comes when you have something much more than a tree....something with lots of cycles and edges scattered here and there. You can imagine that it is harder to decompose such graphs into layers and then to meet all of the other visual aesthetics (e.g. minimized number of edge crossings). It should come as no surprise then that the classic Sugiyama-based approach requires more than just a couple of steps. In total there are four general steps as listed below:
1. Remove all directed cycles.
2. Assign vertices to layers.
3. Reorder vertices within layers to minimize edge crossings.
4. Reassign x coordinates of vertices as needed to get rid of bends produced by "dummy vertices" in layering step.
And maybe as a semi last step or four and a halfish one you'll want to reinsert any edges that you may have taken out in step 1.
Mind you that there is not one fool proof way of tackling any of these steps which are all hard! Many different algorithms and heuristics have been proposed for handling each of them. A case in point regards the first step which I will now discuss: directed cycle removal.
Directed cycles are just what they sound like: cycles that have directions associated with the edges, all pointing clockwise or counterclockwise so to speak. To eliminate the cycles in a directed graph you can take one of two approaches: remove edges from the cycles, or reverse the direction of some of the edges in each of the cycles. Whichever approach you take though it would be nicest if you didn't have to remove that many edges or change too many edge directions. That leads to the so-called minimum FAS (Feedback arc set) problem. The aim is to find a set of directed edges (arcs) whose removal or edge reversal will make the digraph acyclic and that has minimum cardinality. The complementary problem to this is finding a maximum acyclic subgraph of a directed graph.
One algorithm that was proposed for this problem was by Berger and Shor. It works like this: Let what is denoted as Ea initially be the empty set. Pick any vertex from the directed graph and examine its in-degree and out-degree. If the out-degree of v is greater than or equal to its in-degree, then add all of v's outgoing edges to Ea. Otherwise add v's incoming edges to Ea. Once Ea has been updated remove v and all of its edges from the graph and repeat until you can't anymore. The edges within the final Ea will induce an acyclic subgraph (if not then you would have an outgoing and incoming edge for a vertex within Ea but that contradicts the construction of Ea).
Another algorithm that I am currently reading is by Eades et. al. Their algorithm is also easy to explain, though rather than arbitrarily picking vertices the focus is on handling sources and sinks of the graph (vertices that have all outgoing or all incoming edges respectively)and creating so-called vertex sequences out of them. I will not outline the steps of their algorithm as with Berger and Shor but I will explain the intuition behind constructing these "vertex sequences". Suppose that you have labelled a set of digraph vertices as v1, v2,...vn and arranged them horizontally according to that order. Locating the directed edges that go from right to left will pinpoint the edges that finish off directed cycles. Finding a minimal set of edges "against the flow" will then help us in tackling the minimum FAS problem described earlier.
There are many more ways of handling the cycle removal step but I will stop at these two for now. It might not sound so bad up to this point, but keep in mind that this is just step numero uno in the list of four (or four and a half-ish) steps outlined in the Sugiyama framework. Rather than be three quarters empty though I choose to be one quarter full. :-) (Heck! Even if I hadn't read any of this yet I'd be a cup full cause I just love the material so much! <3 ) Perhaps I will go on another one of my random walks now and let the graph info sink in. ;D
References:
Bonnie Berger and Peter W. Shor, approximation algorithms for the maximum acyclic subgraph problem, Proc. First ACM-SIAM Symposium on Discrete Algorithms (1990) 236-243
P. Eades, X. Lin, and w.F. Smyth. A fast and effective heuristic for the feedback arc set problem. Information Processing Letters, 47(6): 319-323,1993
It was not long ago that I officially proclaimed the start of my graph visualization journey on this blog. Two days into this analytic expedition of sorts I have already come across a branching path in the graph visualization world. One sign is pointing me to the chaotic land of hairballs, visualization cowboys darting back and forth to catch the nasty buggers with their algorithm loops. To the other path I see a sign pointing to a rather different sight, a land in which all species of hairball have gone extinct. In the fields of this unusual land I see what appear to be delicately woven tapestries floating about in space. What is this new breed of graph creature and where could it have possibly come from?
As it turns out, deep down these tapestries are the same as the hairballs of the first branch's wild wild west. About a year ago a new cowboy came into town, bringing a rather different set of tools to help with the hairball infestation. Hairballs straying too close to the other side of the path are bound to meet defeat. Looking through the cowboy's set of tools you won't find the usual assortment of loop lassos and heuristics ammunition. No. Instead you will find a comb with the word BioFabric written over the handle.
What is this BioFabric? BioFabric I have found out is a Java-based tool for the visualization of networks. Even those with only a brief exposure to graph visualization will find a plethora of tools throughout the Internet with different algorithms and capabilities for solving their complex data drawing problems. So,..., what makes BioFabric so different? What makes this cowboy stand out from the rest? What's the deal (in Jerry Seinfeld voice) with my unusually fluffy writing and short story-like introduction? I will say one word: lines!
Now all of us graphsters and graphistas (males and females who like graph theory)are used to seeing lines for edges when we look at graphs. What I'm talking about are not edges though, but vertices. Rather than having the picture be made up of dots and lines we have lines and lines; specifically the vertices get drawn as horizontal lines and the edges between become vertical lines. Don't get it? Here I've made a few small examples showing what a few graphs drawn according to the traditional approach would look like if given the lines against lines treatment.
The first example is the simplest of them all. We're just visualizing the graph of one dot (or K1 to be correct in graph lingo) as a horizontal line. What about the graph of two dots with a line in between (i.e. K2)? That will end up looking kind of like an I. The third graph which is the first cycle of the bunch (and K3 incidentally) will look kind of like a wind-chime after straightening things out (yeah...lame joke :-P).
With those simple examples you should now have a slightly clearer idea of what I mean when I say graphing lines against lines. But these examples are small potatoes. If we are looking at graphs of this size or ones that are relatively small to the hairballs that I keep talking about, then the traditional approach would probably be a lot clearer to understand and eyeball for analysis. However, the focus of the last so many graph theory posts have not been about looking at these "small" manageable graphs, but rather the really scary monstrosities that have been replicating at an alarming rate in the land of hairballs. Those are the kinds of graphs that really benefit from the BioFabric treatment. The real power of BioFabric approach comes from the fact that your vertices become horizontal lines that can be of ANY length. Because said vertices can be as long as they wish, you won't have to worry about those horrid edge crossings anymore! If adding another edge to the graph runs the risk of introducing crossings to your visualization, just make the vertex longer and tack new edges to the end of it. The idea is that simple!
Of course we've all been told time and time again that the devil is in the details, and some of you may be suspicious that this simple idea is too good to be true when you try to think how to organize the vertical and horizontal edges throughout this graphical mesh. If you do a little bit of reading up though (reference paper shown below) you will see that there is a very clear and systematic approach taken for this kind of layout scheme. So for my analytically minded readers who are not satisfied with just hearing that something is good without knowing why, I assure you that there is order and method that cleverly does the work just described.
Now I have just been introduced to this new concept of graph visualization which is pretty ground shaking for me, the graph drawing traditionalist who always imagined vertices as dots. I am not a close-minded person though and find this new approach to be intriguing, interesting, and definitely promising! I plan on exploring this topic further and comparing it with the many vertex as dots approaches and see what kind of differences I find between the two general methods. I strongly encourage all of you to read up more on BioFabric's take on graph visualization. At the bottom I have provided links to the website of BioFabric and to a paper discussing the basic ideas behind it (it even talks about all of those darn details I was just telling you about!) Enjoy!
..................................................................
Short Story Afterword:
Long ago people were frightened at the possibility of the earth being round. It's not round! It's supposed to be flat! Hundreds of years later it appears that we have now reached a somewhat similar phase in history. I can hear the graphsters and graphistas saying: "Those vertices aren't supposed to be flat! They're round I say! Round!". Do you ever get the feeling of deja vu? (in Groundhog Day voice) :-)
Link to BioFabric website:
http://www.biofabric.org/
Link to paper discussing BioFabric:
http://www.biomedcentral.com/content/pdf/1471-2105-13-275.pdf
Now when I use the word trickery in this post's title, I am not talking about any sort of drama (as those of you who have seen my Downton Abbey graph may be thinking). Sorry to disappoint but there will be no lies, betrayals, jealousies or schemings. No, my math trickery is much more peaceful and magical thank that. I have rolled up my math magician sleeves and have created a neat little mathematical proof with my trusty wand (i.e. my pencil). Below is a proof that I wrote recently for a matrix theory class that I am currently taking. I am pleased with it because it rather gracefully avoids some of the gory details that can crop up in problems like these that involve identifying eigenvalues.
Here is the problem: For the general n by n matrix consisting of all 1's (call it J), show that the only eigenvalues of J are 0 and n.
Proof:
One way to go about this proof is by performing row reductions and linearly combining the columns (these operations won't alter the determinant for finding eigenvalues). However, rather than go through all of that calculation business which trips me up sometimes, I'll do more of a direct proof.
Suppose that x is the n by 1 eigenvector corresponding to an eigenvalue of J. Finding an eigenvalue corresponds to solving the system (tI - J)x = 0 where t is the eigenvalue and 0 is the zero vector. The matrix tI - J has (t-1) in the main diagonal and -1's everywhere else. If we multiply this out by x = [x1, x2,...,xn] we get the following system of equations:
(t-1)x1 - (x2 + x3 + .... + xn) = 0
(t-1)x2 - (x1 + x3 + ... + xn) = 0
.
.
.
(t-1)xn - (x1 + x2 + ... + x(n-1)) = 0
From the n equations above we can express the sum x1 through xn in the following form:
(*) x1 + x2 + .... + xn = (t-1)xi + xi = t*xi for all i = 1,...,n
Now let's add up all of the n equations shown above before *. This gives us:
(t-1)(x1 + x2 + ... + xn) - (n-1)(x1 + x2 + ... + xn) = 0
This simplifies to:
(t-n)(x1 + x2 + ... + xn) = 0
Substituting in (*) we then get:
(t-n)*t*xi = 0 which is true for all i
Now clearly t = n and 0 are eigenvalues. To show that these are the only eigenvalues of the all 1's matrix, assume that there is an eigenvalue t of J not equal to n or 0. Dividing by (t-n) and t we then get that xi = 0 for all i. That is a contradiction though because x is an eigenvector and eigenvectors are assumed to be nonzero. Therefore the only eigenvalues of an n by n all 1's matrix are n and zero.
I like this proof because it is clean and gives the result through a little bit equation manipulation. An advantage of following the messier row reduction method (not shown here) though is being able to see the multiplicities of the eigenvalues as well as the general form of the corresponding eigenvectors. Clearly, both proof approaches have their merits.
Fin :-)
Going back to my whole hairball analogy (from previous posts), if you do any generic google image search for graph theory, you are bound to come across pictures of really complex graphs (from a distance I think that they look like my dogs' hairballs). Analyzing these can be a beast,..., so much that anything (and I mean ANYTHING) that could lighten the load on our machines and brains is most welcome. That is where the topic of this post, graph visualization, comes in.
Just as there are lots of different graphs out there, (the number of possible graphs on n vertices shoots exponentially as n grows), there are lots of different ways of drawing out those graphs, some methods especially made for graphs with a particular structure. The drawing method that I am introducing you all to now falls under the circle-based graph layout category. That's a mouthful! Basically what it means is that you position your graph's nodes along the perimeter of a large invisible circle and then draw the edges/lines in between nodes for all of the connections that you have. Below is an example of a simple circle-based graph visualization.

The idea is simple enough, but can easily be expanded on. What I pictured above is the crudest kind of circle based visualization that you could have for a graph. Remember that the idea behind any visualization is to make something about the graph's structure clearer to see and interpret. How are we supposed to glean any information from something that looks like an arts and crafts project from grade school? The solution is to impose additional aesthetic criteria on it and see if we can design algorithms to do at least a partial cleaning of the visual mess created. To be more specific about what this "partial cleaning" entails, it means that we would like to minimize the number of edge crossings (points where edges meet in the drawing that aren't vertices.
This is an area that I have just recently begun to explore. So far I have read up on the following approaches discussed by Yehuda and Gasner (see paper reference below).
1. order the vertices about the circle's perimeter in a way that will be less akin to fostering edge crossings
2. take some of the edges that cross on the inside of the circle and have them loop around the circle's exterior instead (a.k.a. exterior routing)
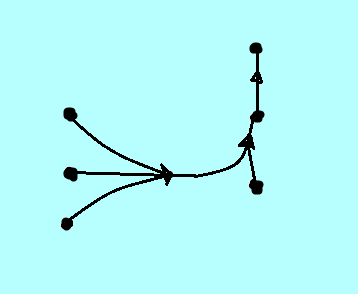
3. find densely bunched groups of edges and rather than drawing all of them individually, have one edge represent all of them. This representative edge will split off into several smaller edges at its very ends so that it is clear what edges were being represented. This edge bundling saves ink and makes the structure of the graph easier to interpret. Another way to think about it is like having a cherry twizzlers rope and you pull at the ends a little bit so that at either end of your rope you have these little "danglies" hanging. The "danglies" were bunched together in the middle which serves as the representative edge in this case. Uggh....hope that that made sense. Not the most sophisticated sounding example I'm afraid. :-P
As I find out more of the specifics regarding implementation of these ideas I will discuss them in later posts. Specifically, what I am looking into right now is how to identify those edge bunches that I was just talking so much about. :-)
The impression that I've gotten so far in my readings on graph visualization is that it is a very experimental field. There are so many different things that can affect the visualization of a graph that I imagine it must be hard to prove things. When this is the case a good approach to tackling the problem is to identify several key parameters and adjust them experimentally to see what matters, what doesn't, and which of your ideas pan out. At the very least I expect that I will be doing quite of bit of experimenting in the "graph theory lab". Much safer than experimenting in the chemistry lab I will say! :-D
If you are interested in reading more about this post's topic then I recommend looking at the following paper. It goes into detailed discussion over the 3 approaches to improved circle based visualization listed earlier.
Reference: Koren Yehuda, Gasner Emden R., Improved Circular Layouts, AT&T Labs-Research, Florham Park, NJ 07932, USA